

Data pipelines have no announcements to make when they break. When a KPI looks wrong in a board report, your analytics team realizes that a field type has changed upstream, there is spike in the Kafka consumer lag, 18% of rows were dropped silently by JOIN.
The business value evaporates from the gap between failure and detection. A 2026 enterprise data infrastructure benchmark report suggests that pipeline downtime and operational disruption costs an estimated $3 million average monthly business losses to large enterprises. 500 senior data and technology leaders confirmed that such incidents take nearly 13 hours to resolve on average.
What are the best practices for building a data pipeline?
A working data pipeline cannot be called a robust data pipeline. A fault-tolerant, observable, idempotent, and horizontally scalable pipeline is a robust data pipeline. Below are the six best practices for building robust data pipelines. They address each failure mode in sequence, and resolving the previous one builds on the next step.
Practice 1. Design Idempotency before writing transformation code
Idempotency is the process of re-running any data pipeline stage with the same inputs, expected to produce the same input of no duplicate records or no inflated aggregates. However, it is the most overlooked attribute of a production-grade pipeline.
Kafka, Kinesis, and Google Pub/Sub all guarantee at-least-once delivery, but it is not exactly-once. Your pipeline will certainly give duplicate events, in any retry scenario right from a pod restart to a network blip and even manual backfill. Duplicate records are likely to increase silently, and corrupt other aggregates built on them, if you depend on INSERT only transformation.
- The fix has to be a process where outcomes are entirely predictable and fixed, with no element of randomness.
- Use source_id and event_timestamp to build a composite key.
- At the write layer, leverage MERGE or UPSERT semantics.
- Use Snowflake’s MERGE statement, BigQuery’s MERGE DML, or Redshift’s UPSERT pattern to enforce these at SQL level.
- Handle large-state deduplication using Kafka transactions and a RocksDB state backend for streaming workloads on Apache Flink.
The explanation above answers why idempotent pipelines are non-negotiable in production. It will fix idempotency. Next you should be taking up structural. It will help you fix what to do when the data that arrives is incorrect, incomplete or irrelevant.
Practice 2. Enforce schema validation at data ingestion
Schema drift is the silent villain that makes data pipelines fail miserably. Imagine your data pipeline has no schema enforcement at the ingestion boundary, and in such a situation the upstream engineering team changes a data type from string to integer, renames a JSON field, or adds a required column without notice. These changes will propagate into your raw layer, will break downstream dbt models, and silently nullifies aggregates.
456 analytics engineers, analyzed 11M+ tables to conclude that the most challenging problems is data quality. Of which, Schema drift accounts for 7.8% of all root-cause data quality incidents.
The problem is big and requires immediate attention. The best solutions include:
- Shift schema enforcement to second priority and enforce structure before data enters the raw zone.
- For Kafka-based pipelines use Confluent Schema Registry or AWS Glue Schema Registry to validate every event at produce-time
- Reject non-conforming messages before they get into your data pipeline.
- For batch ingestion you can utilize Great Expectations or dbt schema tests in the pre-load validation steps.
- For forensic analysis and reprocessing after resolving the upstream schema, you can route malformed payloads to a dead-letter queue (DLQ)
Once clean and validated data starts arriving, think about where it should land and how it should move through your data architecture.
Practice 3. Separate raw, transformed, and serving layers
One logic bug is enough to lead you to full re-ingestion if you are depending on a pipeline that writes directly from source to final mart. It is advised to separate your data pipeline into three different storage layers known as Bronze-Silver-Gold architecture or Medallion architecture.

A transformation bug in the Silver layer will never disturb or impact the Bronze copy. The isolation between layers does magic. At times of logic error, you can re-run dbt against the existing Bronze data without pulling a full re-ingestion from the source system. Expert analytic service providers would build dimensional models in the Gold layer tailored for your BI workload. They will also ensure that the query patterns get mapped to partition and clustering keys from inception.
The best thing of using isolated layers is that it limits the blast radius for every single failure. Though effective, isolation alone does not tell you when something breaks. For that you require end-to-end observability instrumented across every stage.
Practice 4. Instrument every stage with data observability
Remember, data pipelines without observability are pipelines you cannot trust. A pipeline that fails completely and loudly is better than a pipeline, which delivers 40% null spike, in a critical column, upon successful completion. It indicates silent data degradation, where pipeline runs but the output is completely incorrect. Data analysists term it to be the hardest failure class to detect in absence of a dedicated observability instrumentation.
Research by Monte Carlo & Wakefield, suggests that on average 67 data quality incidents happen every month across organizations. Detecting these incidents takes more than 4-5 hours in 68% of them, and 15+ hours goes in resolving the discrepancy once the incident is discovered.
Data observability is completely different from pipeline logging. It tells you whether the data is trustworthy or not, whereas logs tell you whether a job ran or not. Here are the four instruments at minimum:
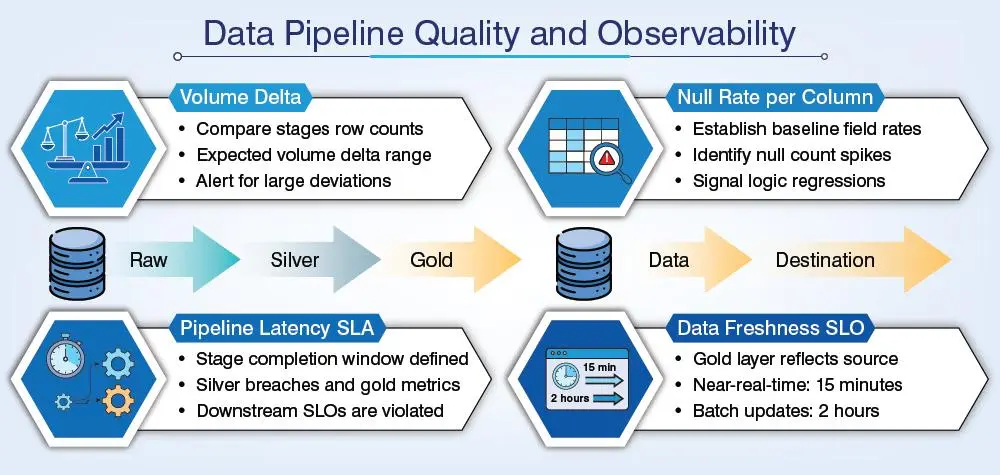
Tools that you use, may be Airflow and dbt, for the activity will vary depending on orchestration layers. Teams that require code-defined test suites with version control should leverage great expectations. Ultimately, the tool should notify anomaly detection, not just job failures. It will empower your team to catch degradation before the downstream users does.
You have learnt how to catch problems in production. So, design architecture to handle growing data without the need to re-engineer the pipeline.
Practice 5. Build for horizontal scalability, not just current volume
Design scalable data pipeline architecture before you need it. Re-architecting while scaling up is not a feasible option. Vertical scaling including adding memory and CPU to existing nodes has limitations. On top of it, once you hit it while managing peak load, options become very expensive and limited.
Horizontal scaling including addition of workers and consumers, or computer nodes, can help you scale linearly and is a viable strategy to meet enterprise data volumes. Design decisions that determine the scalability should be made well in advance and cannot be retrofitted for sure.
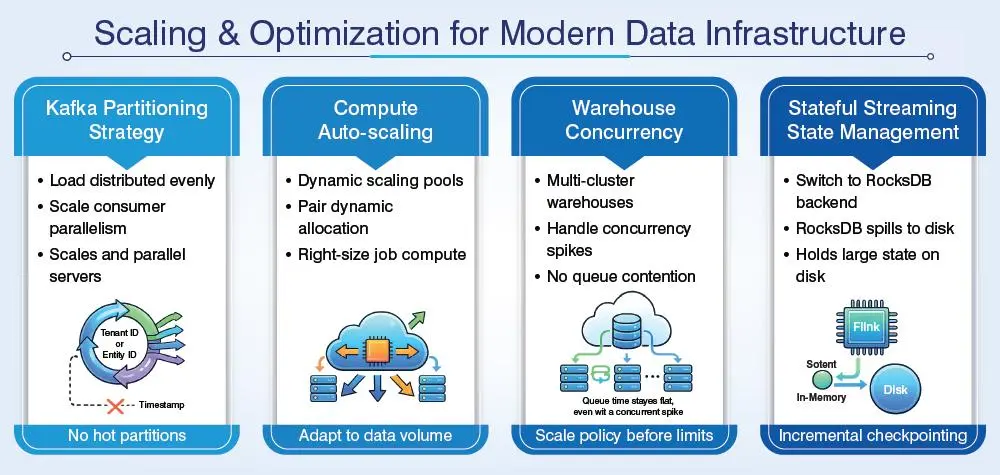
Design ingestion and transformation covers 10x of your current peak volume, and the storage is inexpensive. However, re-architecting a pipeline serving live production traffic proves to be a costly affair.
Scaling up the data pipeline will equip you to handle growth in data volume. Now is the time to make the scalable data pipeline an auditable and trustworthy data asset. Let’s look at the final best practice that addresses data governance.
Practice 6. Implement pipeline-level data governance and lineage tracking
Lineage tracking converts a data pipeline into an auditable data asset. A KPI moving unexpectedly without a lineage will mandate your team to check upstream tables, review recent changes in dbt model, and querying transformation logic across three tools. This activity is tedious and time consuming, but column-level lineage reduces it to minutes.
Every field right from ingestion event to BI visualization can be mapped using column-level lineage. It will help you assess which source table it came from, which all transformations touched it and which all downstream reports depend on it.
A change in the filed upstream, lineage will accurately and instantly tell you which dashboards, models, and pipeline stages are affected. You can use this details to assess the impact before merging a schema change rather than after.
A 2025 data integrity trends and insights report by Precisely & Drexel University suggests that only 12% of organizations have data of sufficient quality and accessibility for effective AI implementation. But the absence of column-level lineage is a primary barrier to data trust.
Implementation options vary by stack:
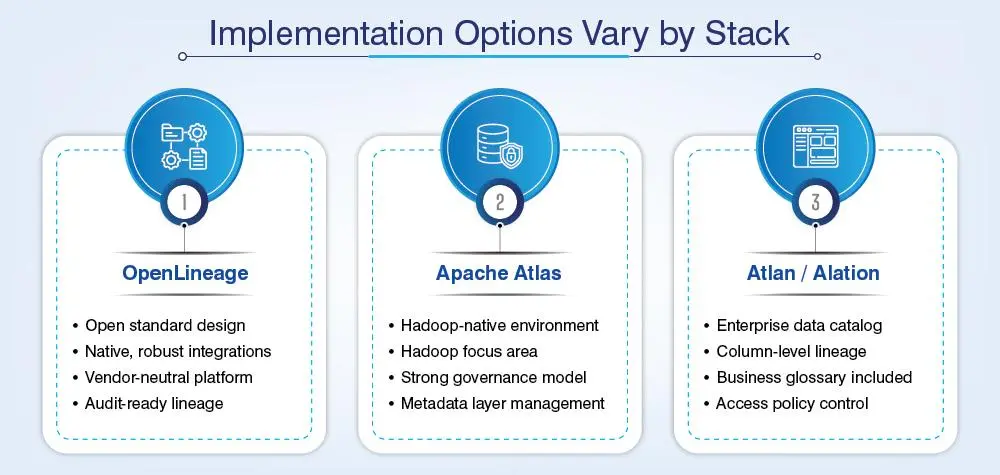
Governance is not something that you apply ad hoc. It has to be access control codified in pipeline configuration.
Defining Snowflake’s RBAC, BigQuery’s column-level IAM policies, and Redshift’s column-level grants as infrastructure-as-code and versioned alongside your data pipeline logic is advised.
Also, because you did not give importance to governance, make sure compliance requests do not become an everyday hurdle. In order to make you warehouse serve fast and trustworthy data; ensure you embed column level lineage and access policies in your data pipeline.
Conclusion – Six best practices are a system, not a checklist
The six best practices compound the value of the ones before it. A data pipeline with no idempotency, but with observability will alert you about duplicate-driven volume spikes. But what about a clean path to remediation. Similarly, a pipeline with no schema can only take you to the source of malformed data but will not show you how to fix it.
If your team is spending more time training incidents instead of building, or your pipelines are triggering silent failures, and your warehouse reflects yesterday’s transformation logic; what you need is an architecture with a structured view and not any incremental patches.


